
Synthetic Data for Testing: The Key to Secure, Scalable Data Migration
In enterprise data migration, a major challenge undermines QA strategies: access to realistic, representative test data without compromising security or compliance. Traditional approaches force a tough choice—use production data and risk violations or rely on limited artificial datasets that miss critical issues.
This dilemma is at a tipping point. The global synthetic data generation market was valued at USD 310.5 million in 2024 and is projected to grow at a CAGR of 35.2% through 2034. Organizations now see synthetic data as more than compliance—it’s a competitive advantage transforming QA into an accelerator.
For CIOs and data leaders facing digital transformation and compliance pressures, synthetic data is the solution. The question is not whether, but how fast to implement it to stay competitive.
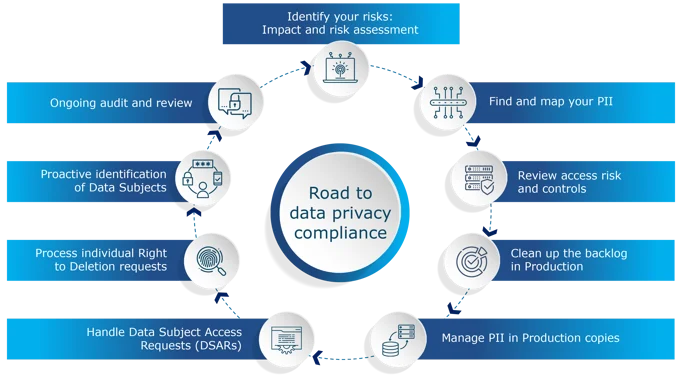
The Testing Data Dilemma: Security vs. Realism
QA teams must test modern applications with realistic data volumes and patterns, while strict regulations (GDPR, CCPA, industry-specific rules) make production data use risky.
The Production Data Risk:
- Regulatory Exposure: High compliance risk using customer data for testing
- Security Vulnerabilities: Increases attack surface
- Access Limitations: Privacy rules restrict data access, causing delays
- Audit Complexity: Extensive compliance documentation needed
The Artificial Data Problem:
- Inadequate Coverage: Fails to reflect production complexity
- Statistical Inaccuracy: Lacks real-world statistical properties
- Scalability Limitations: Manual creation doesn’t scale
- Pattern Recognition Failure: Poor ML model performance
This creates the "testing data gap"—disconnect between QA needs and safe traditional data methods.
Synthetic Data: The Enterprise Solution
Synthetic data generation shifts the paradigm by creating mathematically accurate, statistically representative datasets without linking to real individuals.
Understanding Synthetic Data Generation
It uses algorithms like GANs, GPTs, and VAEs to model new data based on real data patterns.
- Statistical Fidelity: Maintains real data relationships and distributions
- Privacy by Design: Eliminates identifiability while preserving utility
- Regulatory Compliance: Avoids processing personal data entirely
The Strategic Advantages of Synthetic Data
- Unlimited Scalability: Any dataset size for performance testing
- Edge Case Coverage: Test rare but critical scenarios
- Environment Flexibility: Consistent datasets across environments
- Temporal Control: Simulate historical or future data patterns
Transforming Data Migration Operations Through Synthetic Data
Synthetic data moves QA beyond compliance into operational excellence.
Enhanced Testing Coverage and Accuracy
Traditional QA relies on limited production subsets, causing blind spots.
- Volume Testing: Test performance at any scale without large data copies
- Boundary Testing: Simulate edge cases
- Regression Testing: Use consistent datasets for accurate comparisons
- Integration Testing: Compatible datasets for end-to-end system checks
Automation of validations, reconciliation, and data generation creates a unified ecosystem without data constraints.
Compliance-First QA Architecture
Synthetic data simplifies compliance while turning it into an advantage.
- Privacy Protection: Data for ML model training without privacy risk
- Audit Simplification: No need for complex privacy assessments
- Global Operations: Consistent datasets across geographies
- Regulatory Confidence: Demonstrate proactive privacy measures
Operational Efficiency and Cost Optimization
Beyond compliance, synthetic data improves efficiency and cuts costs.
- Resource Liberation: Remove time-intensive data sanitization
- Environment Standardization: Same datasets everywhere
- Team Productivity: No restrictive approvals
- Infrastructure Optimization: Lower storage costs
Advanced Applications: Beyond Basic Testing
Synthetic data provides strategic advantages as capabilities mature.
Machine Learning and AI Development
In 2024, AI/ML training accounted for 45.50% of synthetic data market spend.
- Model Training: Train ML models without privacy concerns
- Bias Detection: Generate balanced datasets for bias checks
- Performance Optimization: Test AI systems under diverse scenarios
Advanced Scenario Testing
- Disaster Recovery: Simulate failure scenarios
- Capacity Planning: Project future data for scalability tests
- Security Testing: Include attack patterns for validation
Addressing Data Quality Challenges
Synthetic data proactively addresses quality issues before production.
Continuous Quality Monitoring
- Pattern Validation: Ensure synthetic data mirrors production
- Statistical Monitoring: Continuously validate statistical properties
- Feedback Integration: Refine generation algorithms based on performance data
Quality-Driven Generation
- Business Rule Compliance: Adhere to business logic
- Referential Integrity: Maintain proper dataset relationships
- Temporal Consistency: Preserve realistic time-series patterns
Strategic Implementation: Best Practices for Enterprise Success
Successful implementation aligns tech, business goals, and compliance.
Executive-Level Considerations
- ROI Measurement: Track cost savings and improved compliance
- Risk Mitigation: Frame as risk reduction
- Competitive Positioning: Use as a differentiator
Technology Integration
- Platform Selection: Integrate with existing QA tools
- Scalability Planning: Ensure growth capability
- Quality Assurance: Intelligent automation offers superior pattern recognition
Organizational Change Management
- Skills Development: Train QA teams on synthetic data use
- Process Integration: Seamlessly incorporate into workflows
- Stakeholder Alignment: Communicate benefits beyond compliance
The Future of Enterprise QA: Synthetic-First Strategies
Synthetic data mastery offers significant competitive advantages amid growing complexity and regulations.
Market Evolution Indicators
Projected to reach USD 9.3 billion by 2032 at 46.5% CAGR, showing broad adoption.
- Regulatory Pressure: Privacy laws make it essential
- AI Integration: Synthetic tabular data use triples by 2030
- Competitive Differentiation: Better testing and compliance than rivals
Strategic Implications for Data Leaders
- Investment Priorities: Treat as infrastructure, not tactical tool
- Innovation Enablement: Safer, more aggressive strategies
- Market Positioning: Offer stronger privacy guarantees
Conclusion: The Imperative for Synthetic Data Excellence
Relying on production data risks compliance; artificial data compromises quality. Synthetic data solves both problems, transforming QA into a strategic capability.
For CIOs and data leaders, the choice is clear: lead or follow in adopting synthetic data for secure, scalable, comprehensive QA.
The future is synthetic-first, and the timeline is measured in months, not years.
Investment today determines tomorrow’s competitive edge.








{kind=link}